Study Note
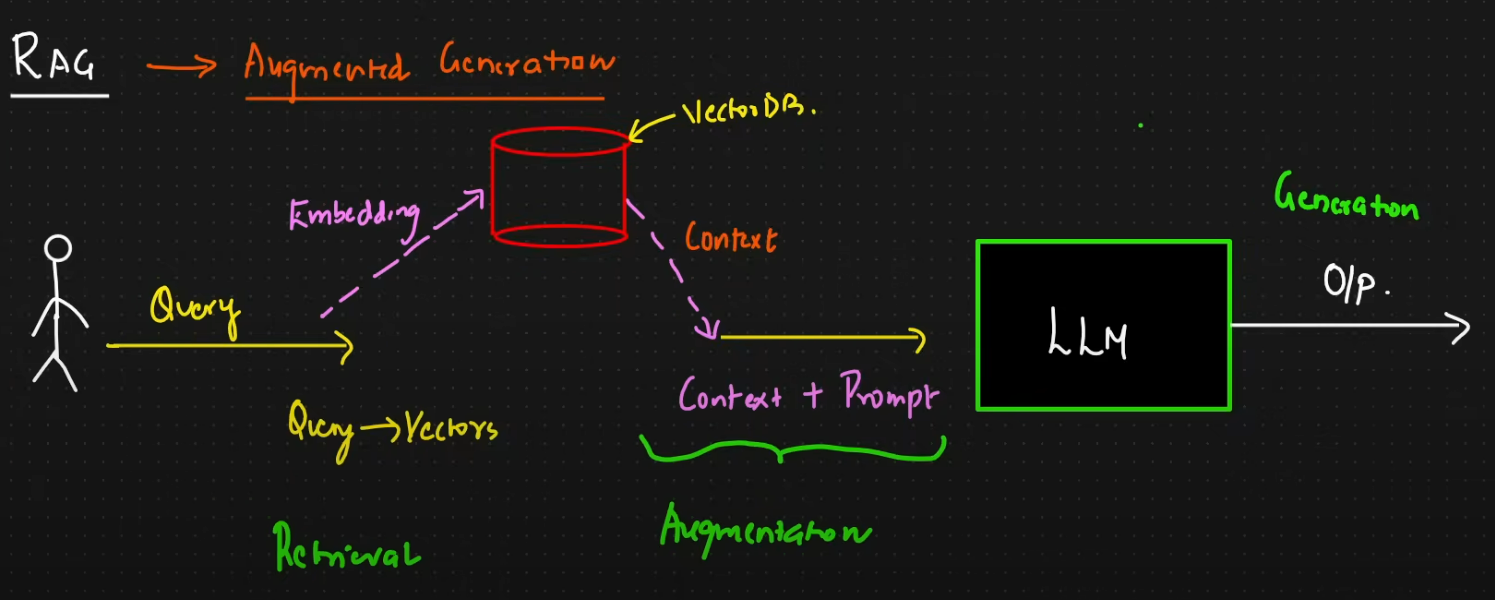
RAG (Retrieval-Augmented Generation)
May 19, 2026·2 min read
AIRAGLLMvector-databases
What is RAG, Actually?
- Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response.
- Large Language Models (LLMs) are trained on vast volumes of data and use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences.
- RAG extends the already powerful capabilities of LLMs to specific domains or an organization's internal knowledge base, all without the need to retrain the model. It is a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts.
CONS of only using LLMs
- LLMs are trained on a specific set of data, suppose knowledge cut off is a month ago, so for current world data it will hallucinate.
- Also it cannot access private or internal data such as HR policies, finance docs etc.
- Fine tuning is a very expensive and tedious process because it involves tweaking billions of parameters.
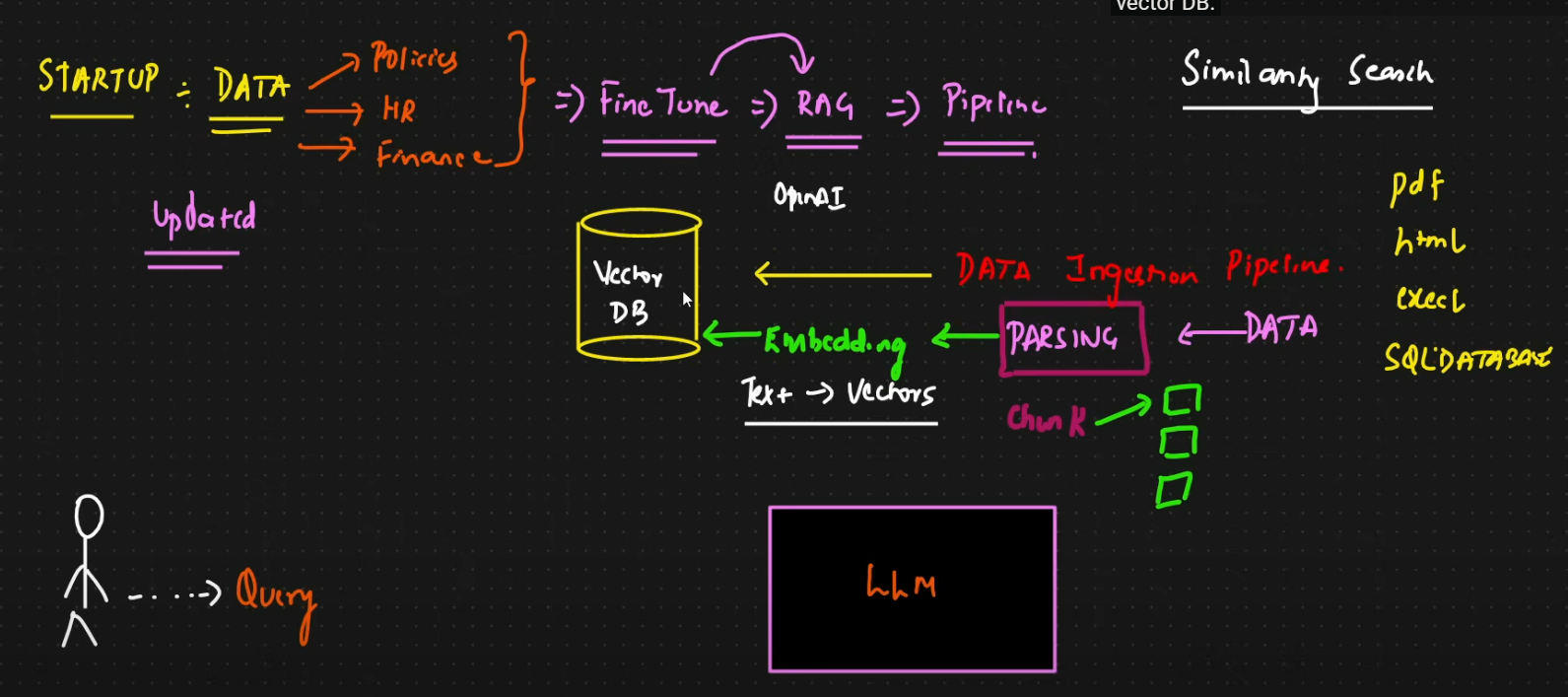
Data Ingestion Pipeline
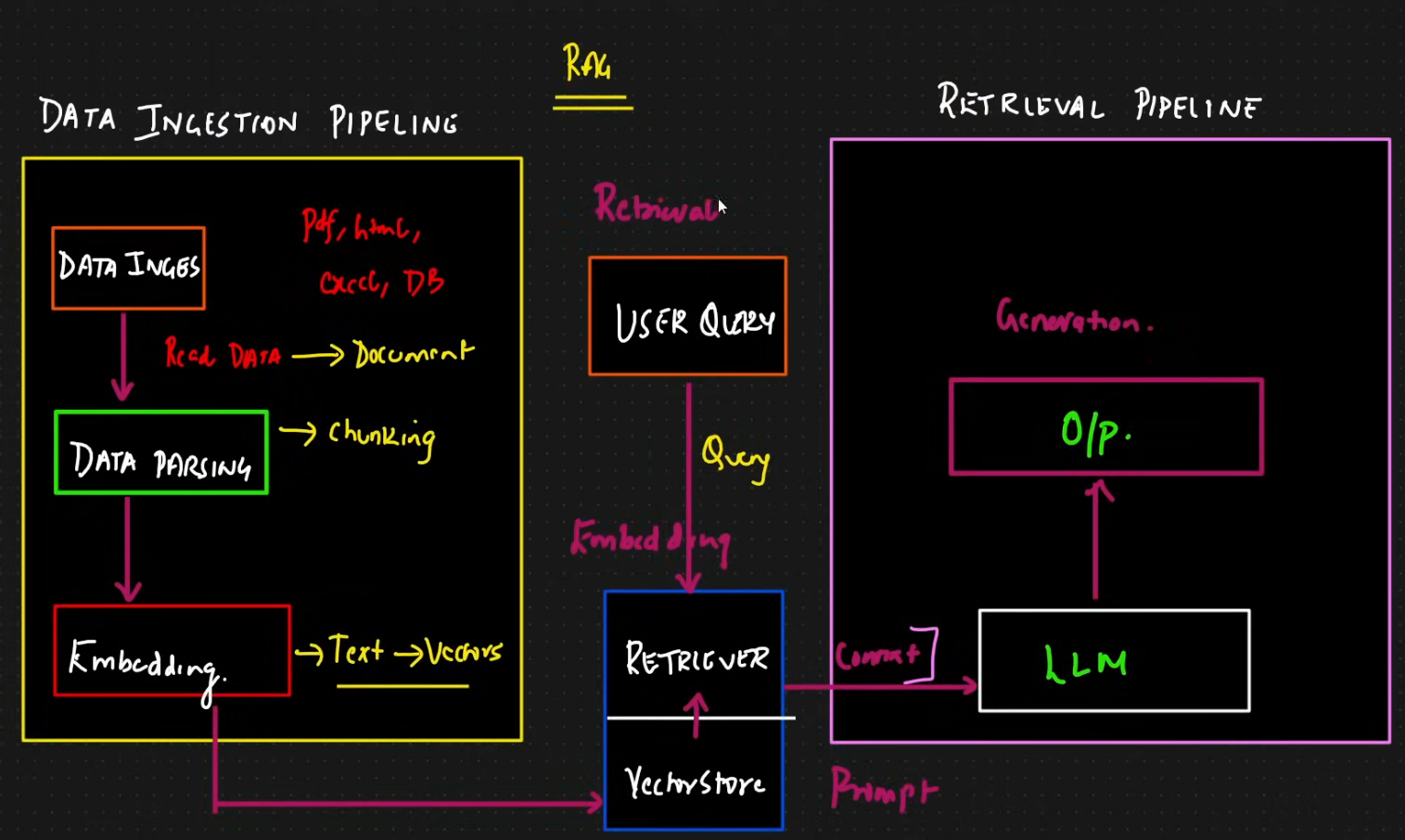
Similarity Search
- Technique used within the RAG pipeline to find info relevant to user query from a database.
- To perform — text data is converted to vectors using embedding models
- The user query is also converted to vector, the system applies algorithms like cosine similarity to compare query against the vectors in the vector DB.
- The search identifies the
chunks of datamost similar to the request, this retrieved info is calledcontext, which is then sent to LLM to help it generate an accurate answer.
Semantic Search
Semantic search is an advanced search method that goes beyond keyword matching to understand the user's intent and the contextual meaning of a query.